
The production:
- AI game called Werewolf: bots play the social-deduction game against each other and against people, trying to pass for human while they do it. Under the hood it’s a Next.js app with its data in Firestore, its logs in Better Stack, and eight different AI providers wired in by API key, because the whole point is watching models from rival labs try to out-lie each other.
- A couple of static sites in the mix too, including this blog, each on its own domain, each with a renewal clock to keep an eye on and a visitor count worth knowing.
Here’s everything I wanted to keep an eye on:
- Eight AI provider budgets. The credits that keep every model in the game. Most run on free tiers, which means I pay for them. I need to make sure my keys don’t run dry.
- The app’s own error logs, shipped to Better Stack - the exceptions and 5xx errors that never make it into the database.
- In-game failures recorded in the game database, when the engine breaks a game mid-play.
- In-game user statistics: it’s exciting to see new users and what people are doing in my app.
- Cloudflare: every deploy, DNS zone, SSL certificate, and domain-renewal clock.
- Visitor traffic to the static sites, this blog included, from Cloudflare’s privacy-first Web Analytics.
- The loop itself: did every scheduled task actually fire, did any of them crash, is anything stuck waiting on me past its deadline.
So it isn’t one thing, it’s a pile of integrations, and not all of them are easy to automate. Some (GLM, Gemini, Mistral) can only be automated via browser. No token, no CLI, nothing to call.
Reading logs is a bit more than it sounds. It needs on-the-fly analysis so I’m not woken up in the middle of the night for false positives or low-impact issues.
User metrics are important - I want to see new registrations and what people are doing in my app. And how they spend my money via API calls. And… in fact, I don’t know what I want exactly. Some good balance between too much noise and dry key stats would be nice.
And I need notifications on my phone with stats and numbers.
So I prompted Claude Code to build a task-based system running in a loop. Everybody talks about loops lately, it’s the hottest topic in agentic AI. Usually it goes like ‘stop prompting your agents, and prompt loops’, and then 20k likes and shares. Well… this writing is more on the implementation end. I built one of those loops.
The loop
It’s really simple. Just configure this thing to run every 20 min or so:
# launchd (or cron) fires this every 20 minutes, in the project dir:
claude -p "Grab the next task off the queue and work it until it's done or you time out."claude -p is print mode - it runs headless, does the work, prints, and exits. No interactive session, no human at the
keyboard. That one line is the whole heartbeat.
It runs from a directory where CLAUDE.md explains that Claude has one goal - get a task from a queue and work on it until a criterion is met. Or until it times out. Repeat this 24/7. What tasks are and how they get into the queue? That’s where jobs come in - they create tasks on a scheduled basis. Give this instance of Claude Code a bunch of tools it may need to call APIs, to use a browser, to send notifications to Telegram. And run this whole thing 24/7.
Here are my jobs:
- monitor_keys - twice a day. Remaining balance for five providers (DeepSeek, Moonshot, xAI over a balance API; OpenAI and Anthropic over a cost API minus a baseline I set once).
- scrape_stats - daily. The browser one. Logs into GLM, Gemini, and Mistral and reads the credit straight off the dashboard.
- monitor_cloudflare - daily. Pages deploys, DNS zones, SSL expiry, domain renewals, plus blog traffic.
- monitor_health - every six hours. Scans the games for broken ones, urgent if the engine gave up on a game mid-play.
- monitor_betterstack - hourly. Reads the app’s error logs back out of Better Stack and pings me on any new error line.
- werewolf_stats - daily. New users, games created, how much the AI burned.
- self-audit - daily, and it runs outside the loop on purpose, so a broken loop can’t hide its own failure.
Each one is just a cron line. When a job comes due the scheduler drops a task on the queue, the loop picks it up on the next tick, runs the matching handler, and writes back what it found.
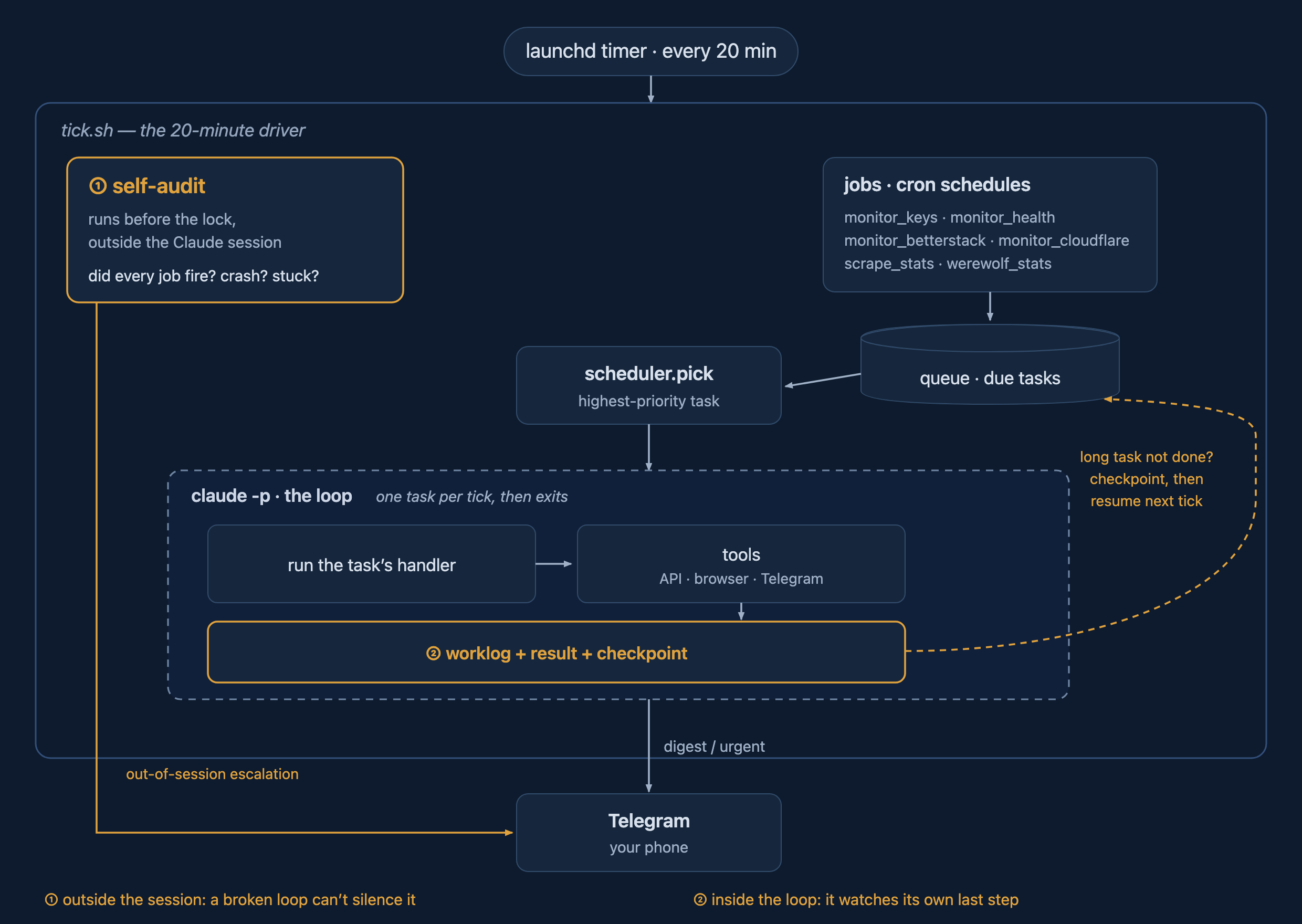
The whole heartbeat. The self-audit ① runs outside the session so a broken loop can’t silence it; the worklog step ② is how a long task hands itself off to the next tick.
Intelligence
That part about user metrics I wasn’t sure about - I put my uncertainty into the prompt. Here is the data with read-only access, just go figure. The model can collect deltas over different timeframes and see the patterns. New users, what the most active ones are doing, how many games they create.
When the AI sees an error, it doesn’t simply report it back to me. It checks the database, finds the user, the game, its state. It tells me whether the error is recoverable or terminal. It guesses what user actions caused this. It’s better than I expected.
The flip side
That same intelligence cuts both ways. This morning the loop pinged me urgent: the Better Stack log host was gone, NXDOMAIN, “BetterStack retired the endpoint between the last clean scan and now.” Confident, specific, even came with supporting evidence - sibling hosts still resolve, so it figured this one got pulled.
It was wrong. One DNS lookup failed, that’s all. I checked by hand: the host resolved fine on every resolver I tried, the API answered on the first request, and the next scheduled scan would have passed on its own without me ever knowing. A transient blip. The model took a single failed lookup and reasoned its way into a whole vendor-retirement story, then woke me up over it.
A dumb script would have logged “lookup failed, retry next tick” and moved on. The smart one is the one that talked itself into a false alarm. That’s the tax on the intelligence: when it reads context well it saves me a database dig, and when it over-reads it invents a problem that isn’t there. The fix isn’t less intelligence, it’s boring escalation logic in front of it - make a check fail a few times in a row before it’s allowed to wake me.
How to build such thing
Brainstorm with Claude Code, agree on the design, and let it do the job. That’s it. The whole thing can be vibe-coded in an hour. And give it a month to run and polish itself with your help/feedback.
The boring part is integrations. You need to create all the keys, secrets, Telegram bots. Find a safe way to hook this
all into the agent. I keep mine in the launchd plist that schedules the loop. The LaunchAgent has an
EnvironmentVariables block, the secrets live there in my home directory, well outside the repo, and the tick inherits
them as environment variables every time it fires. The repo only ever references the variable names, never the values.
The one credential that isn’t a key, the read-only Firebase access, is just a file path
pointing at ~/.config. Nothing secret is ever committed.
Self-monitoring
A loop runs without you. It fires every 20 minutes whether you’re looking or not, the tasks are complex, and there are a lot of them. They often fail for whatever reason, and you don’t want to be debugging this. So you end up having to monitor your monitoring system. The way out is to let it monitor itself.

The self-audit is the agent with a stethoscope to its own chest - did every job fire, did anything crash, is anything stuck waiting on me. And it runs outside the loop on purpose, because a check that lives inside the thing it’s watching can’t hear it flatline.
A few things made the core reliable:
- Every task writes a worklog - what it did, what it found, what broke. A hook compacts them when they grow too big, so the record never rots.
- Claude Code is told to record the problems it hits, not just the happy path. The failures are the useful part.
- One check runs outside the session. A tick can die mid-run and never get the chance to report it, so the audit that asks “did every job fire, did anything crash, is anything stuck waiting on me” can’t live inside the loop - a broken loop can’t tell you it’s broken. It runs before the loop’s own session and outside it.
- Compaction hooks to keep worklogs short.
- And it can reach me. Anything it can’t handle itself goes to Telegram.
It took a while, but the core got solid: it’ll pick up any task and reliably report what happened, good or bad. That’s the whole point - once you know about the problems, Claude Code can usually fix them itself.
Reports
I created a Telegram bot and let my loop control it. It’s simple and very convenient.
The routine days are boring on purpose. A morning digest reads like this:
Cloudflare: 0 Pages, 2 zones - all green. (aiwerewolf.net cert ~36d, azelianouski.dev ~69d)
Console scrape: GLM $8.96 (LOW, < $10 - top up soon, alongside DeepSeek), Gemini $0/$250, Mistral $0.62/$30. Clean, no urgent.
Blog traffic (7d): azelianouski.dev 8 visits (3 yesterday).
Werewolf: +2 users (124 total), 1 game, $0.00 since yesterday.
Nothing in there needs me. It’s a status line I read with coffee: keys have runway, sites are green, a couple of people showed up, nothing’s on fire. The loop even narrates its own limits when it has them:
[self-audit] Claude session limit hit 1x in 24h - tasks re-queued (not lost), retried after reset.
That’s the texture of a normal day. The point of all the plumbing is the abnormal one.
Long tasks
Each tick is time-boxed. It has to be - the next one fires in 20 minutes, and you don’t want two of them stepping on each other, so a task gets a wall-clock budget and gets killed if it runs over. Most tasks finish in a minute. But some don’t: a long write-up, a multi-step scrape. Those can’t run start to finish in one session.
The trick is checkpoints. A task that’s going to run long writes its progress into a small state blob and marks itself in-progress instead of done. The next tick sees in-progress work, resumes it before it picks anything new, reads that checkpoint back, and carries on from where the last session stopped. A long job just spans a few ticks instead of one.
Counters are the other half. Every monitor remembers what it already saw - a set of fingerprints for the log lines, the list of games already broken, yesterday’s balances. On each run it reports only the difference. That’s the whole reason the thing isn’t constantly crying wolf: the first time it looks it quietly baselines whatever mess already exists, and after that only the new stuff is news.
And because all that state would otherwise sit on my laptop waiting to get lost, a nightly job commits every durable artifact - digests, reports, memory - and pushes it. The runtime junk is gitignored; what’s left is a real backup.
Summary
It’s cool. But it’s also hard to get it to a reliable, solid state. It took me a month to put all the use cases together and to finally stop finding bugs and problems here and there. Not too often, at least.
A lot of loop-experts claim that tests can help you with the reliability. Cover everything and throw the humans out of the loop. “It’s called automation”. Yeah, maybe… Good luck covering integrations with everything I listed here. Good luck covering what you don’t fully know. Oh, and we are talking about vibe-coding here. Good luck with that in general.
What really helps is practice. Vibe-code, build, see what works and what doesn’t. My monitoring is pretty solid right now, it’s very useful, and I had a lot of fun building it.